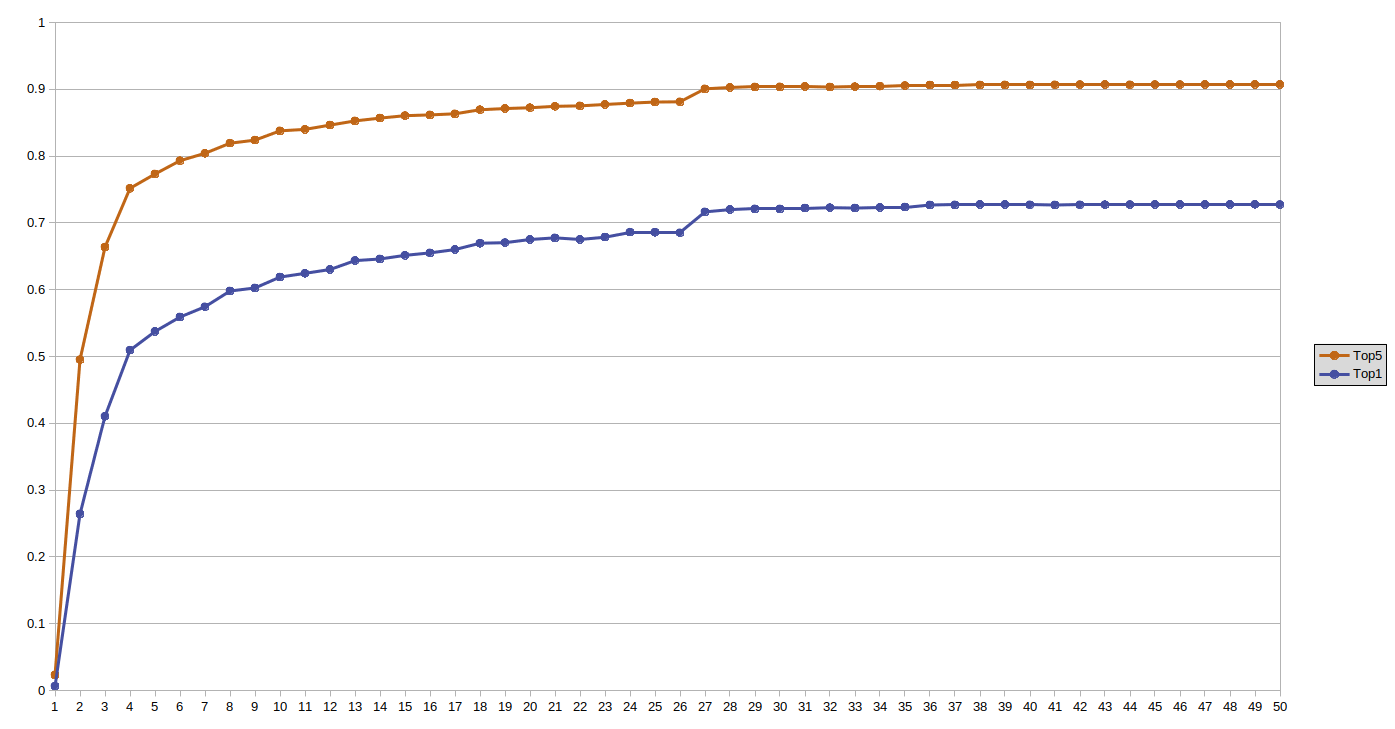
This is a PyTorch implementation of GPT/GPT-2 from the original papers "Improving Language Understanding by Generative Pre-Training" and "Language Models are Unsupervised Multitask Learners" (Alec Radford et al.). GPT is coded from scratch in "vanilla" PyTorch without use of PyTorch transformer classes. The model was trained on part of The Pile dataset comprising of 21.5 bln tokens for only one epoch (the process took about two months on one 8Gb GPU). Even after one epoch of training the model exhibits ability (albeit clearly well below human level) to generate sensible prompt completions. The model achieves perplexity=19.35 on the validation set.
Full article