PyTorch implementation of Transformer from scratch from the original paper "Attention Is All You Need".
This is a PyTorch implementation of Transformer from the original paper
"Attention Is All You Need".
Transformer is coded from scratch in "vanilla" PyTorch without use of PyTorch transformer classes.
The model was trained on UN English-French parallel corpus (about 8 mln sentence pairs after the original corpus of 11.4 mln pairs
was cleaned of too long and too short sentences) and can be used for translation of formal,
official documents (similar to what can be found in UN corpus) from English to French. The model stands no chance to understand
a sentence like:
"Hey dude, we watched an awesome movie yesterday and then went bar hopping.".
While it will do a good job translating a sentence like:
"Despite very serious progress on battling deforestation achieved in the course of the last 12 years,
the area covered by forests is still shrinking, albeit at a slower rate."
to French ("Malgré les progrès considérables accomplis au cours des 12 dernières années dans la lutte contre le déboisement,
la superficie des forêts continue de diminuer, mais à un rythme plus lent.").
The model achieves the BLEU score of 0.43 on the validation set and exhibits close to human quality of translation on 15 long and convoluted test sentences (like the one above) I thought up myself. With Google Translate English->French translation serving as reference for those 15 sentences, the model achieves the BLEU score of 0.57. The model's translations can be viewed here.
My another takeaway is that I'm not certain the BLEU scores should always be trusted blindly to judge the quality of translation. I hired a native French speaker to compare quality of translation the model produced after each epoch of training (the model was trained for 42 epochs). Although the BLEU score on validation set showed no signs of going down, the expert chose epoch 14 as the best and clearly indentified that quality started to deteriorate noticeably after 20th epoch and was significantly lower at the end.
GitHub repository
Preprocessing data
The original UN English-French parallel corpus consists of roughly 11.4 mln sentence pairs. The corresponding files (orig.en and orig.fr) can be downloaded from my google drive:
orig.en - google drive link
orig.fr - google drive link
Download and place them in dataset/UNv1.0/ folder.
Configuration file config.txt that controls preprocessing is in preprocessing/ folder. This is how it looks:
[convert_dataset]
reduction_len=40
N_val=50000
[train_tokenizer]
vocab_size=37000
[remove_too_long_too_short]
max_len=99
min_len=3
[split_into_batches]
approx_num_of_src_tokens_in_batch=1050
approx_num_of_trg_tokens_in_batch=1540
I'll go through different sections of the config file as I describe what different preprocessing steps do. We start with step 0:
$ python3 0_convert_dataset.pyThis step takes the original text files orig.en and orig.fr as input, removes all sentrence pairs with number of words higher than reduction_len (parameter in the section [convert_dataset]), splits into train and validation sets with N_val pairs going to the validation set and the rest going to the train set. Then it saves results to four json files: en_train.json, fr_train.json, en_val.json, fr_val.json in the subfolder after_step_0. Note that the parameter reduction_len controls the maximum number of words in a sentence, not number of tokens. Tokens are not defined yet, as we haven't trained a tokenizer yet and we don't have a vocabulary at this point.
The next step is to train a tokenizer:
$ python3 1_train_tokenizer.pyThis takes train files en_train.json and fr_train.json from the previous step, trains one shared tokenizer (with shared vocabulary), and saves it as dataset/UNv1.0/tokenizer.json. It is a Byte-Pair Encoding (BPE) Byte Level tokenizer. The vocabulary size is controlled by the parameter vocab_size from the [train_tokenizer] section.
Next, we tokenize sentences from all four json files:
$ python3 2_tokenize.pyand save the results to the subfolder after_step_2. After this step each json is a list of lists, with a sentence being represented as a list of tokens.
Next, we remove sentences which are too long (have more that max_len number of tokens) or too short (have less than min_len number of tokens):$ python3 3_remove_too_long_too_short.pyThe results are written to the after_step_3 subfolder.
As the dataset has a fair share of duplicates (about 30%), it's important to make sure that we clean the validation set of entries present in the train set:
$ python3 4_clean_val_of_entries_from_train.pyThis script only affects the val set files en_val.json and fr_val.json. The resulting files are written to dataset/UNv1.0/.
The last step:
$ python3 5_split_into_batches.pysplits the train set into batches. Each batch contains approximately the same number of tokens. Approximate number of source tokens is controlled by the parameter approx_num_of_src_tokens_in_batch in the section [split_into_batches]. The same for target tokens. Approximate number of target tokens in a batch is higher than approximate number of source tokens as French translations are generally longer than their English originals. The results are saved as en_train.pickle and fr_train.pickle to the dataset/UNv1.0/ folder. Each of this pickle files is a list of numpy arrays, with each array representing an English or French part of a batch. During training the order in which batches are fed to the model is shuffled every epoch, but the content of each batch stays the same. The parameters controlling the approximate number of src/trg tokens in a batch should be chosen depending on GPU memory. For GPU with 8GB memory I recommend 1500 and 2100 respectively. The parameters I used in my config file (1050 and 1540) are not optimal for 8Gb and resulted in slightly longer training time.
Training run and run config file
To train the model we need to create a run config file, put it in the run_configs/ folder, and then supply the name of the run config file when initiating a training run:
$ python3 train.py --conf=base_config.txtHere is how a run config file looks:
[train]
device=cuda:0
epochs=42
resume_training_starting_with_epoch=0
num_workers=2
prefetch_factor=10
disable_pin_memory=False
adam_beta1=0.9
adam_beta2=0.98
adam_epsilon=1e-9
warmup_steps=100000
lr_factor=1.0
P_drop=0.1
epsilon_ls=0.1
positional_encoding_wavelength_scale=10000
masking_minus_inf=-1e+6
folder_to_save_state_dicts=saved_models/run_1.0
[inference]
device=cuda:1
epoch=14
inference_method=greedy_search
beam_size=4
length_penalty=0.6
max_len=99
[architecture]
N=6
d_model=512
d_ff=2048
h=8
d_k=64
d_v=64
positional_encoding_max_pos=100
Highlighted in yellow are parameters recommended in "Attention Is All You Need". When referring to sections, pages, etc below, I'm referring to sections, pages, etc from this paper. Six architecture parameters (N=6 - number of layers in encoder and decoder, d_model=512 - model size, d_ff=2048 - inner layer dimensionality of feed forward networks, h=8 - number of heads in multi-head attention, d_k=64 - dimensionality of keys, d_v=64 - dimensionality of values) are specified as parameters of the base model in the first row of Table 3: Variations on the Transformer architecture on page 9 (look at the first 6 columns).
Train parameters P_drop=0.1 (dropout rate) and epsilon_ls=0.1 (label smoothing) are also specified as parameters of the base model in the first row of Table 3 in columns 7 and 8.
Adam optimizer parameters (adam_beta1=0.9, adam_beta2=0.98, adam_epsilon=1e-9) are recommended in the section 5.3 Optimizer on page 7.
Parameter of positional encoding positional_encoding_wavelength_scale=10000 is implicitly recommended in the section 3.5 Positional Encoding on page 6 (see sine and cosine formulas for PE).
Inference parameters beam_size=4 and length_penalty=0.6 for beam search (only applicable if inference_method=beam_search) are recommended in the section 6.1 Machine Translation on page 8.
The above covers the most critical parameters of the model. The remaining parameters in the config file are mine. The recommended number of warmup steps for the optimizer is 4000 (section 5.3 Optimizer, page 7). The authors, however, ran training on eight P100 GPUs and could fit 25000 source and 25000 target tokens in a batch (section 5.1 Training Data and Batching). I figured, if I include roughly 25 times less data in one step (as I only had one 8Gb GPU), then, probably, I need 25 times more warmup steps. Hence my parameter warmup_steps=100000 in the [train] section of config.
The authors used dynamic learning rate as a function of step number given by formula (3) on page 7:
lrate = d_model−0.5 · min(step_num−0.5, step_num · warmup_steps−1.5)My thinking was that as I use drastically less data for one gradient update, maybe the above formula would require a correction and I introduced a scaling factor lr_factor, modifying the formula to:
lrate = lr_factor · d_model−0.5 · min(step_num−0.5, step_num · warmup_steps−1.5)Having experimented with different values of lr_factor, I realized lr_factor=1 was the optimal value, so there was no need to try to rescale the original optimizer scheduler in the first place.
When running inference, I needed to impose a cutoff on the length of the output sentence. If the model fails to produce end of sentence token (PAD token in my implementation) before this cutoff length is reached, it stops at cutoff then. This value is controlled by the parameter max_len=99 in the [inference] section.
There is no point in re-calculating positional embedding matrix for each batch. It makes more sense to precalculate it for the case of longest possible sentence length and then take smaller slices of it when needed. The parameter positional_encoding_max_pos=100 in the section [architecture] controls the sentence length size of the precalculated positional embedding matrix.
When implementing masked multi-head attention for the decoder we need to set some elements of query-key tensors to minus infinity (so softmax, which follows, would set them to zero). The parameter masking_minus_inf=-1e+6 in the section [train] controls what minus infinity in this context is.
The parameter inference_method in the section [inference] accepts one of two possible values: greedy_search or beam_search (set to greedy_search in my config). Note, that the parameters beam_size=4 and length_penalty=0.6 in the [inference] section are only used if inference_method is set to beam_search.
The parameters num_workers=2, prefetch_factor=10, disable_pin_memory=False in the section [train] control the behavior of the dataloader.
The parameter folder_to_save_state_dicts in the section [train] controls where state dictionaries will be saved on completion of each epoch. Saved files with state dictionaries have names of the form: state_dict_e{epoch_num}.pt, and contain model state dictionary, optimizer state dictionary, and scheduler state dictionary.
The parameter device=cuda:0 in the section [train] controls what device will be used for training. The parameter device=cuda:1 in the section [inference] controls what device will be used for inference. The parameter epochs=42 in the section [train] controls the total number of train epochs (no need for such a large number, epochs=20 or lower will suffice). The parameter epoch=14 in the section [inference] controls what saved model will be used for inference (saved model after what epoch). The parameter resume_training_starting_with_epoch in the section [train] is used if we need to resume training from a particular epoch (if the last saved model was for epoch 7 and now we want to resume training from this point, we set resume_training_starting_with_epoch=8).
My trained model exhibits peak performance at epoch=14. You can download saved state dictionaries for this epoch from my google drive:
state_dict_e14.pt - google drive link
You can put the above file in saved_models/run_1.0/ or in a folder of your choice and change the parameter folder_to_save_state_dicts in the section [train] of config accordingly.
Postprocessing scripts and results
Here is train loss as a function of epoch number:
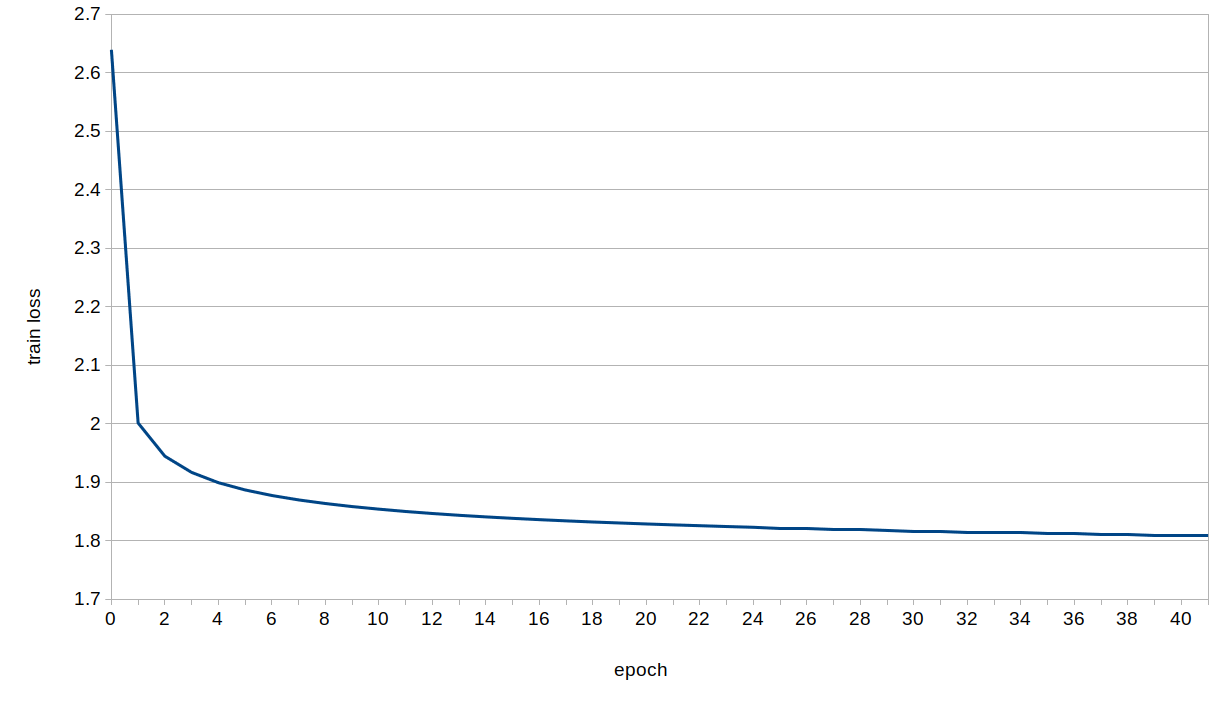
To calculate the BLEU score on the validation set run:
$ python3 bleu_score_on_val_set.py --conf=base_config.txtHere is how BLEU score on the validation set (for the first 5000 entries) behaves as a function of epoch number:
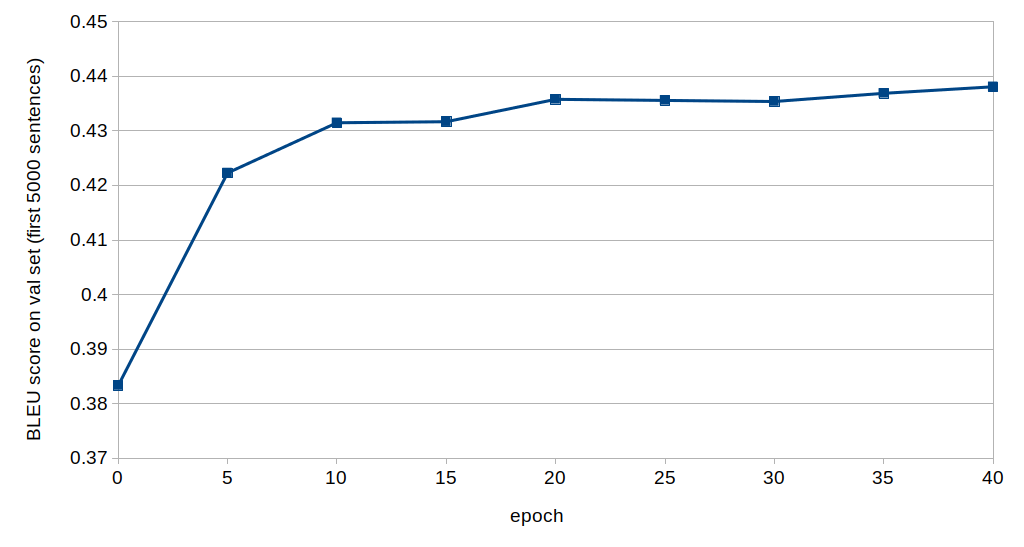
To calculate perplexity on the validation set run:
$ python3 ppl_on_val_set.py --conf=base_config.txtPerplexity on the validation set is 2.32.
Now let's take the first 100 sentences from the validation set and produce their French translations with Google Translate. Let's still treat reference translations provided by the UN as the ground truth, and let's measure BLEU score of the model translations and BLEU score of Google Translate translations against these UN reference translations. Here is the script that does it:
$ python3 bleu_google_100.py --conf=base_config.txtThe model's BLEU score is 0.38, the BLEU score of Google Translate is 0.36. I only use this comparison as a sanity check. Not as a "proof" of superiority of the model against Google Translate (the reverse is true).
To translate an arbitrary sentence (make sure the sentence is "UN-like") run:
$ python3 translate.py --conf=base_config.txt --sentence="English
sentence to be translated."How reliable are BLEU scores?

Do BLEU scores reliably reflect quality of translation? Should we always chase them?
This is my first experience with machine translation, I'm a newbie to the field, and I can't have a formed opinion. My very limited experience, however, makes me cast some cautious doubt on trusting BLEU scores blindly.
Here is what I did. I thought up 15 long and convoluted test sentences, the likes of which are possible to find in UN documents (please, disregard that some of them refer to thought up events), and then hired a native French speaker to assess quality of model's translation as a function of epoch. The expert was confident that the model performed the best between epochs 10 and 20 (no signs of that in the BLEU scores on val set as a function of epoch), she designated epoch 14 as the best, and she was confident that the quality deteriorated noticeably after epoch 20, degrading substantially towards the end. None of these is seen on the BLEU scores plot shown above.
Here is the script that produces translations for these 15 sentences:
$ python3 translate_my_own_15_sentences.py --conf=base_config.txtThe best result (corresponds to epoch=14) can be seen here. If we treat Google Translate translations of these 15 sentences as ground truth, the model achieves the BLEU score 0.57.