Traffic sign recognition in TensorFlow 2.x.
Published in November 2019

GitHub repository
Clone my GitHub repository for Traffic sign recognition to follow code specific parts below.
Data
Basis of the dataset
My final dataset is the result of compilation from a number of sources. The basis is a LISA (Laboratory for Intelligent & Safe Automobiles) dataset available here. LISA dataset is a set of frames with annotations, out of which I extracted images of traffic signs with labels. I chose to keep only 12 categories of US traffic signs, as they were best represented.
Here is the list:
- Added Lane
- Left Curve
- Right Curve
- Keep Right
- Lane Ends
- Merge
- Pedestrian Crossing
- School
- Signal Ahead
- Stop
- Stop Ahead
- Yield
Any traffic sign which does not fall in one of the above categories (or even if it does, but not a US sign) will not be recognized by the neural net.
As some of the images were in grayscale, I had to convert everything to grayscale. Next, I threw away images that were too small (some signs were as small as 6x6 pixels), and I also purged very low-quality images (yes, I had to actually look at all of them). At the end of this stage, I was left with around 5,000 images.
Dataset augmentation
After I formed the basis of the dataset as described above, the images were not even nearly uniformly distributed between the selected 12 categories. Some categories had noticeably smaller number of images than others. Initial training confirmed that the dataset will benefit from augmentation, with the focus of this augmentation on the under-represented categories. I augmented the dataset in three different ways:
- Youtube
- Drive around and take pictures
- European datasets
This proved to be time consuming, but nevertheless the most effective way. There are lots of dash cam videos on youtube. You can stop the video when you see a traffic sign which you want for your dataset, make a print screen, and later (after you aggregated lots of print screens) crop and label the pictures. As the basis dataset had lots of stop signs in it, but not so many merge, lane ends, and yield signs, I focused more on highway than on city videos. I spent around 30 hours on youtube, and generated around 500–600 new images from that. It is not a lot percentage-wise, but as those images were mostly in badly needed categories, this improved accuracy very substantially.
I asked my wife to take pictures of traffic signs as we drive. We got 250 photos, out of which only under 100 were used for the selected 12 categories. We live in Canada and our left curve, right curve, pedestrian crossing signs differ from the US versions. We also deliberately took pictures of signs outside of 12 categories to use as negative examples (more on this later).
Belgium traffic sign dataset is publicly available at the time of writing, German dataset was available for downloading when this work was done (maybe you still can download it from somewhere else). As European stop signs look the same as the US, I took this category from the above datasets. That was easy but didn’t make much difference as I already had a good number of stop signs in the dataset.
After augmentation, I ended up with 6,180 reasonable quality images in 12 categories.
Negative examples
Adding negative examples is easy, all you need to care about is that you don’t accidentally place a “positive” image (image with a traffic sign from one of 12 categories) in your folder with negative examples. The bulk of my negative examples came from Belgium and German traffic sign datasets (after I carefully removed from them what might be close to positive examples), and from previously discarded LISA dataset categories. I added 53,820 negative examples to the dataset, thus making its total size 60,000 (6,180 positive + 53,820 = 60,000 total). After I added negative examples to the dataset I observed a substantial drop in false positive rate (that is when the neural net claims to recognize an image as a traffic sign from one of the above 12 categories, while in reality there is either no traffic sign at all or a sign not from these 12 categories).
When labeling negative examples in vector space I was faced with a choice. One option is to label them with 12 dimensional vector with zeros everywhere (the image does not belong to any of 12 categories). The second option is to label them with 13 dimensional vector with 1 in 13th position and zeros everywhere else (belongs to the newly created category #13), while all positive images will have 0 in 13th position and 1 in one place somewhere else. I had somewhat better results with the option 2 (13 dimensional space), so this is what’s implemented in the code presented.
Final training dataset files
Training dataset consists of two numpy files: X.npy - images, and Y.npy - labels. Array in X.npy has a shape (60000,32,32,1) - 60,000 images scaled to 32x32 pixels, 1 channel (grayscale). Array in Y.npy has a shape (60000,13) - labels for 60,000 images, each label is a 13 dim vector with single 1 and twelve zeros. Thus [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0] labels category #4 - Keep Right, [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1] labels negative example (no traffic sign from 12 categories).
Files X.npy and Y.npy get loaded into dataset/ folder first time when you run training. Alternatively you can download them manually from my google drive:
X.npy - google drive link
Y.npy - google drive link
Test set and scoring system
As I only had to deal with 12 categories, I could afford a luxury of building a test set completely separately from the training set. Splitting one dataset into train and test sets (which is a regular practice) might sometimes give us a false sense that everything is OK, while it is not. Neural net might learn “shortcuts” instead of real features, then successfully apply the results of this “shortcut” learning to test examples, which were obtained by the same methods (the same operator, on the same day with the same light conditions, with the same camera, and the same filming techniques, etc …). If, however, test set images are acquired by completely different means, then we expect the results of testing be more rigorous.
Here is what I did. First, I downloaded from the Internet (or used my own) a total of 175 images of traffic signs belonging to my 12 categories. These are some examples:

Then I downloaded from the Internet (or used my own) a total of 130 images of traffic regulation objects not belonging to my 12 categories:

And finally, I downloaded 50 completely irrelevant images:

Numpy arrays pertaining to all the test images are in val_npy/ folder. If you want to see the original photos, you can get them from my google drive:
Now, when the neural net had too low confidence in its prediction of a traffic sign (it thinks it is a Merge sign, but it is only 17% sure), I wanted it to be more cautious. I introduced a threshold parameter, and if the highest probability of a positive answer is below the threshold, then the neural net will return ‘Detection failed’. Basically, I am saying that classifying a Stop sign as Merge is much worse than saying that nothing was detected. ‘Detection failed’ is also returned if the neural net classifies the image into 13th category (no traffic sign from our 12 categories). Accuracy checking scripts allow user to set the threshold parameter. Its default value is 0.5.
I think claiming that Eiffel tower or a golf ball is a Lane ends sign is a bigger error than a failure to detect a Lane ends where it is present. I also think that misclassifying a sign is a bigger error than a failure to detect it. Hence my scoring system:
- The lower the score the better. An ideal infallible model will return a zero score.
- Correct classification of traffic sign adds 0 to the score.
- Correct ‘Detection failed’ (correct statement that there is no traffic sign from 12 categories present) adds 0 to the score.
- Each misclassification of a traffic sign adds 1 to the score
- Each failure to detect a traffic sign from 12 categories where it was present adds 0.5 to the score.
My best trained model has a score of 2.5:
- on 172 out of 175 images with traffic signs from 12 categories it returns correct answers — add 0 to the score
- on 3 out of 175 images with traffic signs from 12 categories it returns ‘Detection failed’ — add 1.5 to the score
- on 1 out of 130 images w/o traffic signs from 12 categories it returns a positive answer — add 1 to the score
- on all 50 irrelevant images it returns ‘Detection failed’ — add 0 to the score
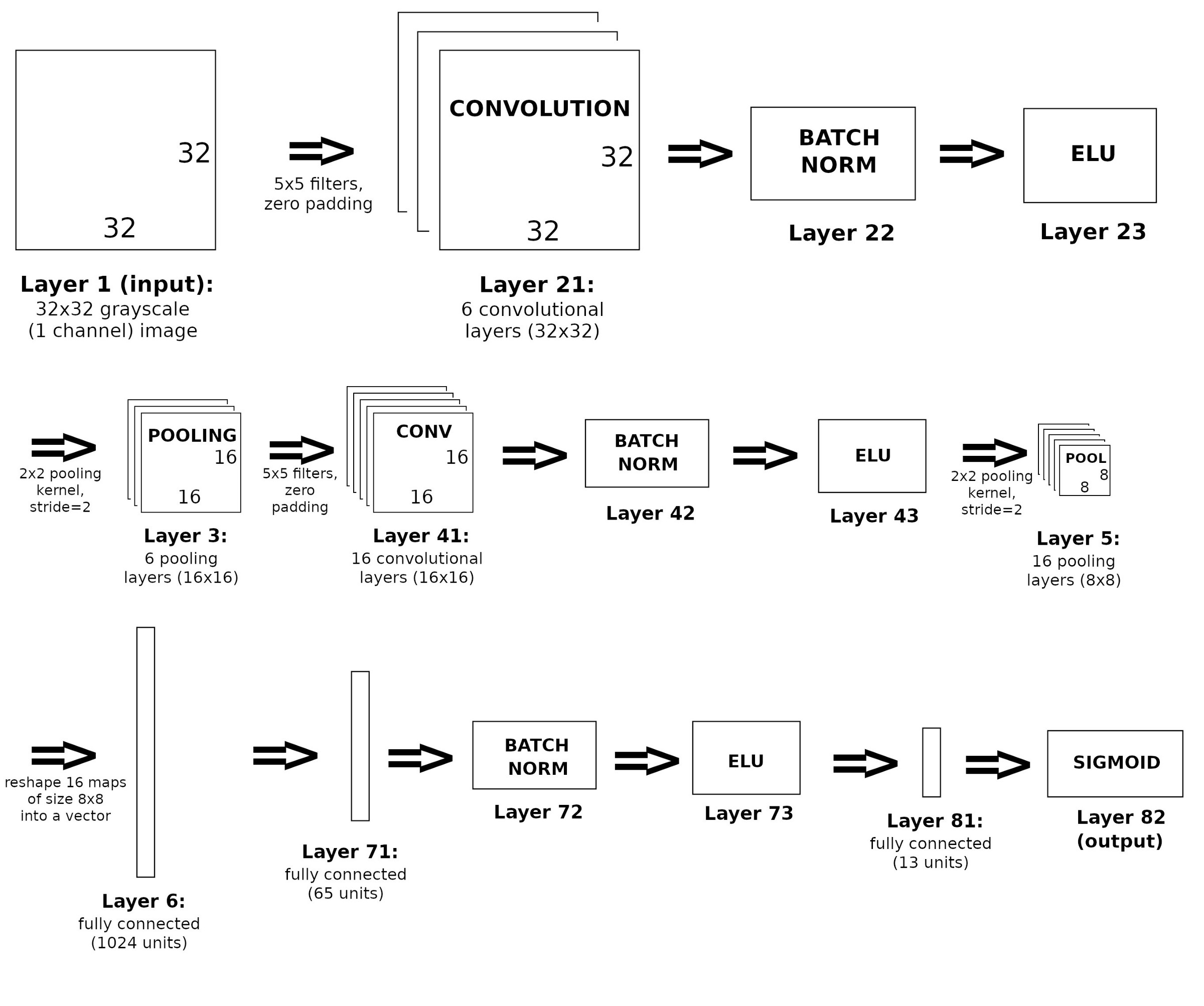
Convolutional Network used
Here is the convolutional network I used:
How to run training/testing, and my results
Train the model
To train the neural net you need to run the script train.py. Here is an example:
$ python3 train.py --save_to_folder testrun --batch_size 1024 --epochs 2000 --dropout_rates 0.6 0.3The first parameter --save_to_folder is required, the other three parameters are optional.
--save_to_folder takes the name of the folder to save the model to during the train process. This folder goes into the directory saved_models. On completion of each epoch the script will be creating a separate subfolder for this epoch and will be placing the current state of the model in this subfolder. Thus if you specify the parameter --save_to_folder testrun, then the result of training after the 0th epoch will be saved to saved_models/testrun/0/, after 50th epoch to saved_models/testrun/50/ and so on.
--batch_size if not specified defaults to 4096.
--epochs (total number of epochs to run training) if not specified defaults to 1000.
--dropout_rates (dropout rates for Layer 6 and layer 7) if not specified defaults to 0.5 and 0.2 respectively.
You can download the results of my best training run from my google drive:
Extract the tar.gz and place the resulting folder sample_results in saved_models/
Check train accuracy
To check train accuracy of the trained model you need to run the script check_train_accuracy.py. Here is an example:
$ python3 check_train_accuracy.py --path_to_trained_model sample_results/999 --thr 0.75The first parameter --path_to_trained_model is required, the second --thr (threshold) is optional.
--path_to_trained_model takes the path to the trained model. You need to specify the particular epoch. In our example it is epoch 999.
--thr (threshold value) if not specified defaults to 0.5
If you run the above example on my results from sample_results you will see that on positive part of the dataset (signs present) the neural net correctly classifies all 6,180 images of traffic signs, and on negative part (signs not present) it correctly returns ‘Detection failed’ in all 53,820 cases.
Find the best epoch
To determine the epoch which gives the lowest score on the test set you need to run the script find_best_epoch.py. Here is an example:
$ python3 find_best_epoch.py --folder_to_load sample_results --epochs 1000Both parameters are required.
--folder_to_load takes the folder with the trained model (inside it it expects to find subfolders corresponding to different epochs).
--epochs — number of epochs to check.
Note that it doesn’t ask for a threshold value. It calculates an average of scores for thr=0.5 and thr=0.75.
In our example find_best_epoch will determine that epoch# 979 is the best with the average score of 3.0.
Show detailed score
If you want to see a detailed breakdown of score for a particular epoch (I always only used it for the best epoch after the best epoch was determined by find_best_epoch.py), then you use the script show_detailed_score.py. Here is an example:
$ python3 show_detailed_score.py --path_to_trained_model sample_results/979 --thr 0.5The first parameter --path_to_trained_model is required, the second --thr (threshold) is optional.
--path_to_trained_model takes the path to the trained model. You need to specify the particular epoch. In our example it is epoch 979.
--thr (threshold value) if not specified defaults to 0.5
If you run the above example on my results from sample_results you will see that on irrelevant images it always correctly returns ‘Detection failed’, it erroneously classifies one image from ‘Signs not in the dataset’ part of test dataset (this part consists of traffic signs not from 12 categories), it correctly classifies 172 out of 175 positive images, and it returns ‘Detection failed’ in the remaining 3 cases. The total score is 2.5.
Check arbitrary photos
Run check_photo.py script if you want to check an arbitrary photo for one of 12 traffic signs the net is trained on. Here is an example:
$ python3 check_photo.py --path_to_trained_model sample_results/979 --imgfile path/to/your/pic.jpgBoth parameters are required.
--path_to_trained_model takes the path to the trained model. You need to specify the particular epoch. In our example it is epoch 979.
--imgfile — path to the image file you want to check.
I am grateful to Waleed Abdulla for his great inspirational article on Traffic Sign recognition.