Coding ResNet-50 from scratch and training it on ImageNet
Published in July 2020
This is a pure training exercise. I wanted to build a relatively large CNN from scratch without making any use of anybody else's code. I also wanted to learn how to handle training on a relatively large dataset.
GitHub repository
GitHub repository for the exercise.
Preprocessing data and training the model
ImageNet training set consists of close to 1.3 mln images of different sizes. The model accepts fixed size 224x224 RGB images as input. At a very minimum, before an image can be fed to the model it needs to be cropped to 224x224 size if the shortest side is at least 224px, or it needs to be re-sized first and then cropped if it originally isn't. In theory, one can preprocess all the images in the dataset first, save their 224x224 versions, and then load those preprocessed images during each training epoch when needed. Although this approach saves preprocessing effort - for each image there is no need to do cropping as many times as there are epochs - it is deeply flawed. The benefits of data augmentation which comes with random cropping (different cropping for each epoch) are just way too significant to give up. The whole preprocessing procedure I'm using here is even a bit more elaborated. Here are the preprocessing steps I'm doing each epoch for each image before it is added to a batch:
- pick a random number from this list [256, 263, 270, 277, ... , 473, 480] (integers from 256 to 480 with step 7)
- re-size an image so the shortest side is equal to the integer chosen at step 1
- randomly crop to 224x224 size
- normalize resulting image (for each RGB channel apply channel-specific mean and standard deviation calculated in advance for all images in the dataset)
- with 50% probability flip the image horizontally, with 50% probability do nothing
- apply slight random color augmentation
The preprocessing steps above have to be done for each image before the image can be included in a batch. Next epoch the same image will have to be preprocessed again. The preprocessing procedure described above takes more time than actual GPU training and would slow down training from one week (I was using one 8Gb RTX-2080 GPU) to a few weeks if GPU had to wait each time the next batch is formed. Here is what I'm doing to avoid keeping GPU idle.
I implemented a preprocessing script runtime_preprocessing.py, whose task is to follow the progress of the training script (training is performed by a separate script) and maintain an up-to-date buffer of numpy .npy files each of which corresponds to a particular batch number. The preprocessing script periodically reads information on the current state of training progress from the text file training_progress.txt and then either does some preprocessing to prepare more batches (which it saves to disk in numpy format) or deletes files from the buffer which are no longer required (if the training process already used them) or both of the above or none. After the preprocessing script does what needs to be done at the moment, it checks whether its services are required again (if the training progressed far enough and buffer needs updating). If not, it goes to sleep for a period of time controlled by the sleep_time parameter in the runtime_preprocessing section of config.txt (I set this to 10 seconds). The preprocessing script will not prepare more than a certain number of batch files in advance, with this number being controlled by the parameter buffer_size in the train section of config.txt (I set this to 1000). If the preprocessing script checks the training progress and determines that the training script still has more than 80% of the maximum buffer size to process, then it does nothing. If less, it deletes old batch files that are no longer needed and then refills the buffer to its maximum size. The preprocessing script uses multiple threads (each batch formed by a particular thread), with the number of threads controlled by the parameter num_of_threads in the runtime_preprocessing section of config.txt (I set this to 3). The training script train.py simply reads numpy files from the buffer folder (I set this up in RAM memory for my training; using SSD would also be fine, just avoid HDD - read/write times for HDD are terrible), converts them to tensors and proceeds with training. If the training script doesn't see the files it needs (meaning they were not yet prepared by the preprocessing script), it goes to sleep for a period of time controlled by the sleep_time parameter in the train section of config.txt (I set this to 100 seconds). If preprocessing parameters are tuned well, the training script will never have to wait.
Here is an example of how to run runtime preprocessing and training.
First, we run the preprocessing script:
$ python3 runtime_preprocessing.py --epoch_start=0 --epoch_end=30 --batch_size=64The command line arguments are self-explanatory. The script will create the first buffer_size number of batches and then it will be waiting. Next, we run the train script in a separate terminal:
$ python3 train.py --run_folder=mytestrun --epoch_start=0 --epoch_end=30 --batch_size=64 --learning_rate=0.01On completion of each epoch, the script will be saving the trained model in a numbered subfolder of mytestrun folder inside saved_models (after epoch 0 it will be saved to saved_models/mytestrun/0/). Note that the batch size specified for training must be the same as for preprocessing. To resume training from a saved checkpoint (saved automatically on completion of each epoch), specify --epoch_start > 0.
Performing step 2 of preprocessing in advance instead of runtime
As stated above, step 2 of the pre-processing procedure is to re-size an image so the shortest side is equal to the integer chosen at step 1 (integers from 256 to 480 with step 7). As re-sizing takes significant time, one might want to prepare 33 folders with re-sized images in advance, before training (that's the strategy I used). An alternative would be to ramp up the number of workers (if enough CPU cores are available) to brute force your way through the bottleneck. If you choose the former approach (this is recommended, and would not require code modifications however trivial), run preprocess.py script (not to be confused with runtime_preprocessing.py) before training with different command line arguments corresponding to different re-sizings:
$ python3 preprocess.py --shorter_side=256This preprocess script will have to be run in advance, before training can start, for each value of shorter_side (integers from 256 to 480 with step 7).
Checking accuracy on the validation set
To check accuracy on the validation set for a range of epochs run:
$ python3 check_accuracy.py --run_folder=mytestrun --epoch_start=0 --epoch_end=30If the trained model for a particular epoch is not available yet (possible if check_accuracy.py is run concurrently with train.py but on a different GPU), the script will wait until it becomes available. When making predictions on the validation set we re-size the image so the shortest side is 256px, then we generate predictions for 10 different versions of the image: crops from each corner, crop from the center, plus horizontal flips of all the crops. The final prediction is the average of predictions on 10 versions. We skip the color augmentation step.
Configuration file
Here is a walk-through for the configuration file config.txt.
Section [preprocess]
ImageNet_folder - path to the original ImageNet folder
path_to_save - path to where preprocess_val.py script will be storing .npy files corresponding to all 10 versions of validation set images
N - number of images in the validation set (50000)
Section [get_mu_sigma]
path_to_save - path where the script get_mu_sigma.py (the script calculating mean and standard deviations
for 3 RGB channels) will write the results to
Section [train]
buffer_folder - path where the training script will be getting batches from (runtime preprocessing script will be writing to this folder)
path_for_saving - path where trained models will be saved to
N - number of images in the train set (1281167)
sgd_momentum - SGD momentum
buffer_size - buffer size used by the train and runtime preprocessing scripts (explained above)
sleep_time - for how long should the train script wait before checking again if the next batch is not available (explained above)
Section [batch_renorm]
Note, the code uses batch renormalization instead of the regular batch norm.
Parameters:
moving_avgs_momentum
rmax_max
dmax_max
start_relaxing_rmax
reach_rmax_max
start_relaxing_dmax
reach_dmax_max
Section [runtime_preprocessing]
sleep_time - sleep time for runtime preprocessing script (as explained above)
num_of_threads - number of threads for runtime preprocessing script (as explained above)
Section [utils]
This section contains values of mean and standard deviation for the normalizing procedure (step 4 of runtime preprocessing). The values are obtained by running the script get_mu_sigma.py.
Parameters:
mu_0
mu_1
mu_2
sigma_0
sigma_1
sigma_2
Section [l2]
l2_penalty - L2 penalty
Results
Here is the plot of validation set accuracies (Top5 and Top1) as a function of epoch number:
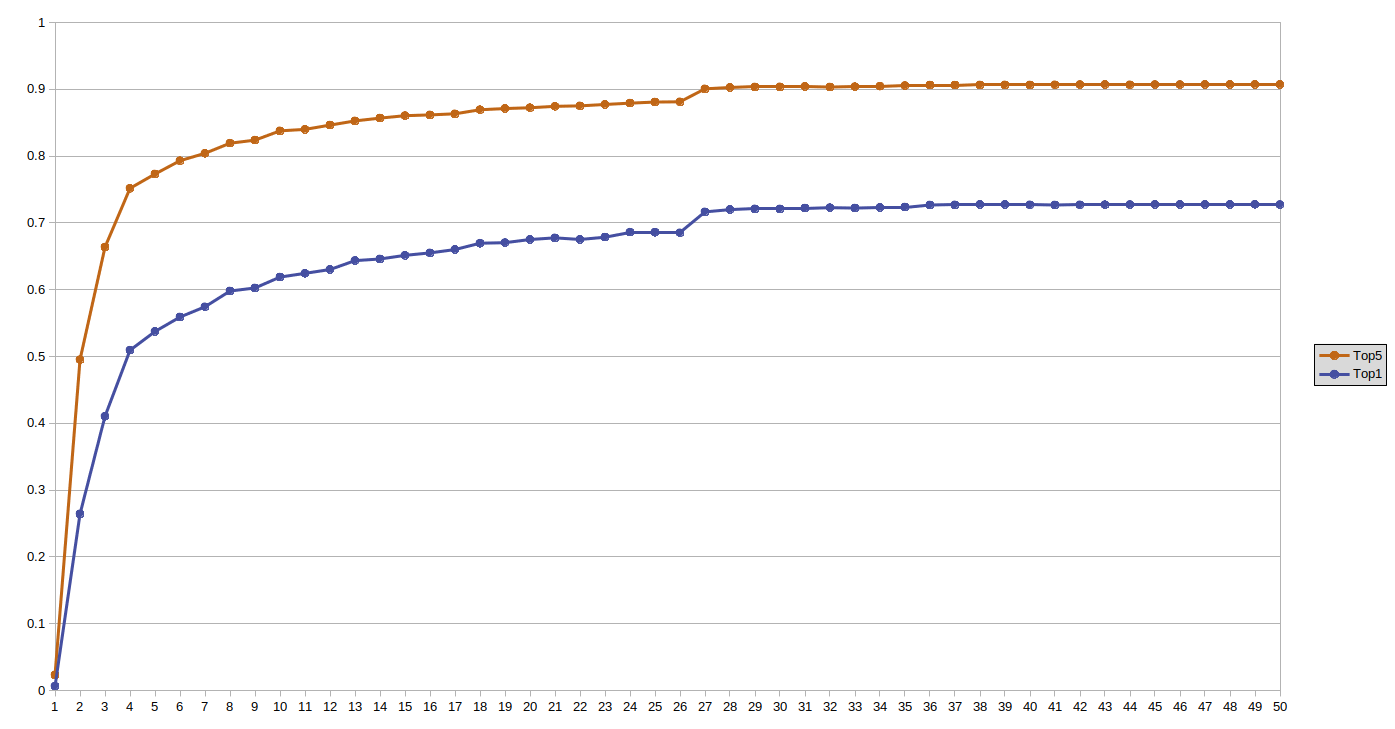
Abrupt increases in accuracy correspond to abrupt changes in learning rate. The achieved top 5 accuracy is 90.7%, top 1 - 72.8%.